
Grover Cleveland converting the U.S.C. to machine-readable xml markup by hand, 1886.
DRAFT COPY: NOT FOR DISTRIBUTION OR CIRCULATION
Most analyses of Congress ask whether a bill passed. Congress itself does not process bills as indivisible objects. It processes text—amending, stripping, substituting, merging, splitting, and rewriting language at every stage. A bill can fail while its language succeeds, absorbed into an omnibus package or a reconciliation vehicle (the budget process that can pass with a simple majority) that bears no resemblance to the original measure. A bill can pass while most of its original text has been removed and replaced. The bill is the unit Congress tracks. The text is the unit Congress actually processes.
Consider a concrete example. If you look up [H.R. 4673](https://www.congress.gov/bill/115th-congress/house-bill/4673/summary/00) in standard congressional data, it shows "introduced" and appears to have gone no further. In reality, its text was folded into the 2018 FAA reauthorization—and that text is now the law of the land. This system detects that; standard data does not.
Existing congressional datasets reflect the bill-level view. They record whether bills were introduced, referred, reported, and enacted. Some measure text similarity between documents. Some credit members whose bills contribute language to enacted law. These are valuable contributions, but they share a structural limitation: they treat legislation as a document rather than as a set of provisions moving through an institutional machine with gates, filters, and decision points that operate below the bill level.
This project builds something Congress has never had: a deterministic reconstruction of how its text actually moves. Built from authoritative XML—the official, structured, machine-readable records published by the Government Publishing Office and the Library of Congress. It formalizes procedure as a finite-state machine with explicit gates. It tracks every atomic unit of legislative text across every version of every bill. It records how text is amended, where it appears, where it disappears, and at which institutional checkpoint it is removed. It classifies the vehicles through which policy travels. And it links all of these layers together at the provision level, so that any paragraph of statutory text can be traced through its full procedural and textual history.
The result is a database that represents Congress not as a collection of bill outcomes but as a structural system—a machine with observable moving parts. The procedural path a bill travels, the gates it encounters, the amendments that modify its text, the vehicles that absorb its provisions, the conference negotiations that rewrite its language—all of these become queryable, measurable, and comparable across Congresses.
With the addition of text embeddings (mathematical representations that capture the meaning of provisions rather than just their wording)—the system gains a new dimension. It no longer sees only where text sits and how it moved. It can see when two provisions are attempting the same policy idea, even if they share no language, no sponsor, and no procedural path. Structure becomes measurable. Meaning becomes measurable. Together, they allow the institutional record to inform not just what happened, but what is likely to happen next.
This paper describes the architecture: what the system contains, how its layers integrate, what research it enables, and how it reframes legislative power at a resolution that bill-level data cannot capture.
At its most basic, this project constructs a deterministic reconstruction of congressional procedure and text mutation from authoritative XML.
Deterministic means the output is rule-based, reproducible, and identical across runs. There is no inference layer. That distinction matters in an age of generative AI: large language models infer and can hallucinate. This system cannot—it is driven by the fixed structure of the XML. Think of it as the accounting ledger of Congress, not the summary. An accountant cannot "infer" a transaction; it either happened or it did not.
Congressional procedure is the formal sequence a bill must pass through to become law—committee referral, markup (the committee meeting where a bill is amended line by line), floor consideration, conference negotiation, enrollment (the final certified version sent to the President), and presidential signature. These steps are not metaphors. They are a defined sequence of institutional gates, each controlled by different actors with different authorities.
Text mutation is what happens to the actual words of legislation as they move through the process. Bills are not static documents. They are living texts that are amended, substituted, stripped, and rebuilt at every stage.
Grover Cleveland converting the U.S.C. to machine-readable xml markup by hand, 1886.
Authoritative XML is the official, structured, machine-readable record of congressional activity. The system draws on two primary sources: GovInfo Bill Status XML (which records what happened procedurally to every bill) and GPO Legislative XML (which records the actual text of every version of every bill). Both are published by the Government Publishing Office and Library of Congress. XML is a structured format in which every section, paragraph, and amendment operation is explicitly marked, allowing the system to preserve hierarchy and detect change without guesswork.
This system reconstructs what is observable from the official record. It does not capture private negotiations, informal leadership agreements, lobbying influence, or strategic intent that does not manifest in procedural action or published text. It models the institutional machinery, not the invisible politics surrounding it.
A note on terminology. Several terms recur throughout this paper. A provision is a discrete paragraph or block of statutory text. A gate is an institutional checkpoint a bill must pass—committee, floor, conference, and so on. A vehicle is a must-pass or otherwise strategic bill that carries other policy—appropriations bills, defense authorizations, and the like. The atomic unit is the smallest indivisible piece of text the system tracks: one XML leaf element per provision.
The database contains five integrated layers.
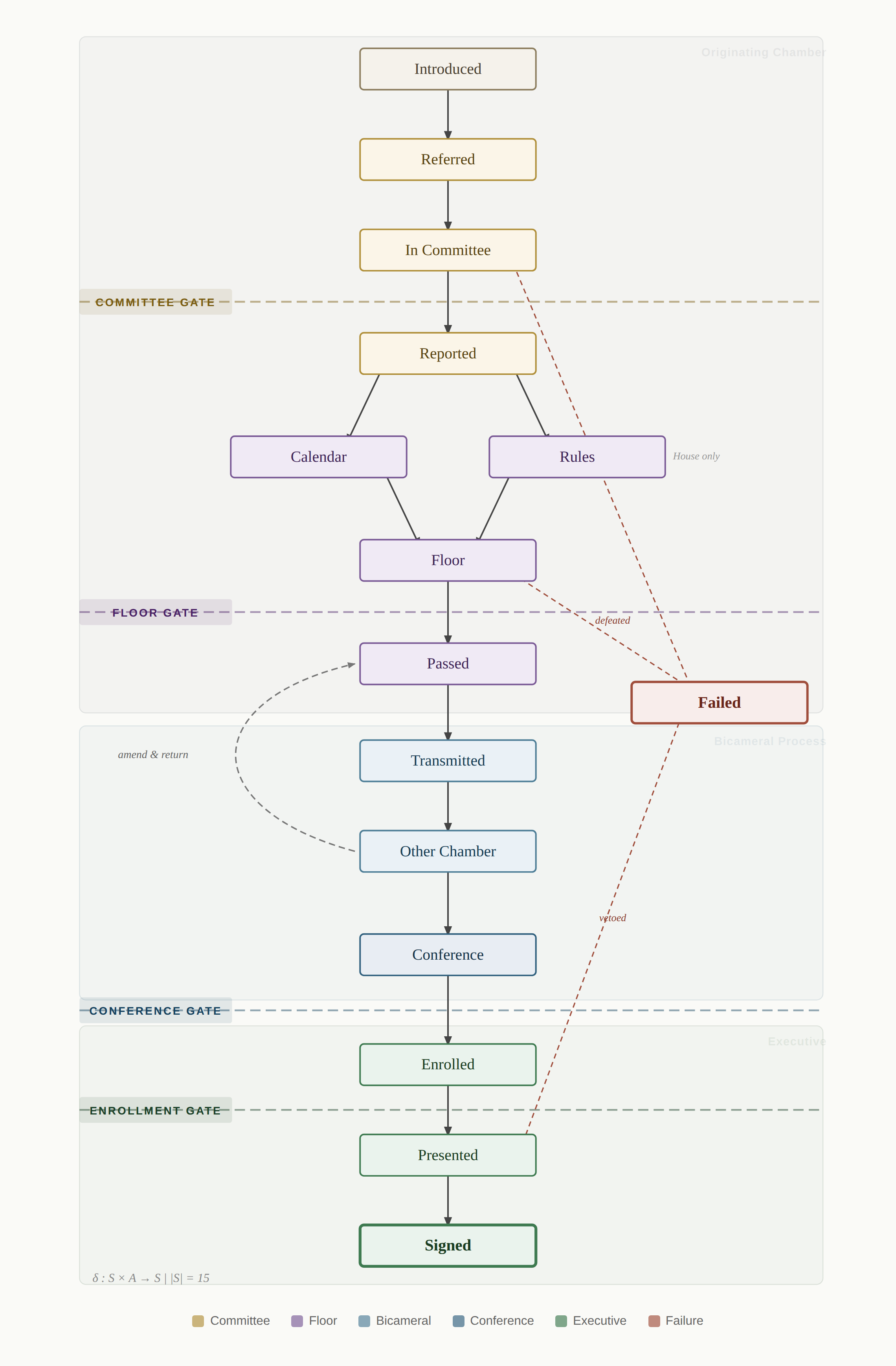
Imagine that every bill in Congress is a game piece moving across a board. The board has specific squares—"Introduced," "Referred to Committee," "Reported," "On the Calendar," "Floor Consideration," "Passed," and so on through conference and enrollment. The rules say which squares you can move to from any given position, and the moves are triggered by specific congressional actions: a committee vote, a floor vote, a motion, a referral.
This database reconstructs that entire board for every bill—15 defined procedural states and a transition function that maps each combination of current state and congressional action to the next state. Action codes are normalized into a canonical vocabulary so that surface-level variations in how actions are recorded (the Senate describes things differently than the House) resolve to the same underlying transitions.
This means you do not merely know that a bill "was reported." You know what state it entered, what gate it passed, what transition rule applied, and whether the transition followed the canonical procedural sequence or represented an irregular path. It is a formal, executable representation of procedure—not a narrative summary.
This layer alone enables research not observable at scale before this framework: measuring whether negative agenda control (the idea that the majority party blocks bills from reaching the floor to avoid votes that would split the party)—operates through procedural routing rather than floor coalition building, testing whether majority-party bills encounter systematically fewer gates than minority-party bills, and tracking how gate configurations have changed across decades of institutional reform.
The state machine abstracts procedural states at the level relevant to text filtering. It does not encode every parliamentary nuance or informal leadership intervention.
Figure 1. Procedural Finite-State Machine: 15 States and Authorized Transitions
Derived from Bill Status XML action codes, 110th–117th Congresses. Dashed lines mark institutional gates; dashed arrows indicate failure transitions.
Every bill accumulates institutional veto points. This layer records them as an ordered stack—the full sequence of gates a bill has cleared.
Each bill accumulates committee gates, Rules gates (House only—the Rules Committee sets the terms for floor debate), chamber gates, conference gates, and enrollment gates. For each bill, this gate sequence is deterministically inferred from the state machine transitions—not coded by hand, not estimated from partial records.
This lets you compare the obstacle courses different bills face. You can measure gate density (how many institutional veto points a bill accumulates), gate sequencing (the order in which constraints are encountered), and procedural bottlenecks (where bills stall and for how long). Not ideologically. Mechanically.
Gate stacks open direct measurement of phenomena central to theories of congressional gridlock. Has gridlock increased primarily because legislators disagree more, or because the procedural machinery has grown more complex? Do bills fail because they lack majority support, or because they are trapped behind procedural bottlenecks? These are different mechanisms—preference-based versus procedure-based—and the gate stack layer allows that decomposition in a way that was not previously measurable in systematic form.
When Congress amends a bill, it is not just "changing the bill." Different amendments do different things—some insert new language, some delete existing language, some replace entire sections with new text, some amend other amendments. Think of the result as a family tree: text has parents and children. If an amendment kills a paragraph, that line of the tree ends. If it modifies text, the tree branches. The database records every one of these operations as a node in a directed acyclic graph (a DAG—because amendments can only apply to prior text, the graph has no cycles), with edges connecting each amendment to the text it modifies and to the other amendments it relates to. The graph is acyclic because amendments can only apply to prior text—you cannot amend something that does not yet exist.
Amendment operations are parsed directly from GPO Legislative XML, where insertions, deletions, replacements, and redesignations are explicitly marked using structured XML elements. From this graph, the system computes node-level mutation (which specific text nodes were altered), overwrite ratios (what fraction of base text was replaced versus preserved), replacement depth (how many layers of amendment-on-amendment exist), and branching factor (how many competing amendments target the same text).
Instead of a flat description like "the bill was amended," you get a mutation graph—a complete structural record of how every piece of text changes across authoritative versions, as observable from structured amendment markup and version releases.
For the first time, questions about deliberative openness that have relied on anecdote and case study become quantifiable. Have floor amendment opportunities declined over time? Has amendment activity centralized in leadership and committee chairs? How often do substitute amendments completely overwrite a bill's text, bypassing the deliberative process? The amendment topology provides continuous, computable metrics for all of these—amendment depth, branching factor, overwrite ratio—across every bill in every Congress in the dataset.
Congress cannot pass thousands of separate bills each year. Instead, it consolidates related policies into vehicles—larger, must-pass bills designed to carry legislative cargo across the finish line. Think of it as legislative logistics: this layer identifies which bills are the prime movers (the engines pulling the weight) and which provisions are the cargo being loaded. This is the infrastructure of passing laws, not "sneaking" things in. In modern Congress, much of the most important legislation travels this way—appropriations, reconciliation bills, or defense authorizations. A bill might be introduced with almost no text—a shell bill—and then have hundreds of pages of policy inserted later via amendment or by the conference committee (the bipartisan House–Senate group that reconciles the two chambers' versions). Other times, a conference committee produces a report that bears little resemblance to what either chamber actually passed.
An important distinction: Suspension bills are small, non-controversial measures (naming a courthouse, for instance) that move quickly on their own. They do not carry other policy. This layer does not target those. It targets vehicles—the freight trains: must-pass giants like the NDAA or an omnibus, designed to carry policy from many committees. The layer identifies which bills are acting as those absorbing engines.
The database identifies and classifies these vehicle strategies automatically, using rule-based structural thresholds applied to measurable properties: the ratio of introduced text to final text, the fraction of conference report language absent from chamber versions, the overwrite ratio of substitute amendments.
The classifications—shell vehicles, conference overwrites, strike-all substitutions (amendments that replace the entire text of a bill or section), reauthorization absorptions (when expiring programs are renewed and other policy is folded in)—are not probabilistic guesses. The thresholds are explicit, declared, and auditable.
That changes the empirical footing of how legislative strategy is studied. When are vehicles deployed—under divided government, during must-pass deadlines, for controversial policy? How often do conference committees introduce substantial new policy that was never considered by either chamber? Has reconciliation been increasingly exploited for non-budgetary policy? These questions have been asked qualitatively for decades; the vehicle layer provides the infrastructure to answer them quantitatively across the full legislative record.
This is the structurally central layer. At the level of individual provisions—paragraphs and subparagraphs of legislative text—the database tracks where every piece of language came from and where it went.
The system treats the smallest indivisible piece of text as the atomic text unit: one leaf node from GPO Legislative XML, identified by a deterministic path that ensures stability across system rebuilds. Each atom links to its structural parent in a full containment hierarchy (atom → paragraph → subsection → section → title → bill), with sibling relationships, cross-references, and dependency edges all explicitly stored and queryable. Lineage is tracked across versions using deterministic rules with explicit method labels—no lineage is ever inferred without recording how it was established.
When text appears between versions without a corresponding amendment record—which happens constantly, because committee markups, manager's amendments (bundled changes offered by the bill's sponsor), and conference negotiations do not generate structured amendment records—the system detects the appearance by comparing authoritative versions and classifies each insertion by procedural interval. That classification is what we call detection context: the stage at which the system first observes the text.
This makes measurable full survival (provisions that persist from introduction to enrollment), partial incorporation (fragments absorbed into other measures), fragment diffusion (language migrating across bills and policy domains), and preloaded dominance detection (identifying when late-stage text overwhelms earlier deliberative content).
This layer supports some of the most practically significant research the database enables. It enables systematic measurement of what I refer to as "ghost bills"—formally introduced measures that appear to fail procedurally, often never advancing beyond committee, yet whose language is later incorporated into enacted law. H.R. 4673, highlighted in the Introduction, is one example: standard data shows it as introduced only, but its text was folded into the 2018 FAA reauthorization and is now law. The system detects that path through lineage edges and atomic units—specifically, text that appears between versions without a structured amendment record, classified as a "Committee Amendment" insertion. Ghost bills are measures whose formal procedural record does not reflect their substantive contribution to statute. The lineage layer makes this phenomenon identifiable and measurable.
It also enables provenance tracking for enacted law, constructing end-to-end lineage chains from introduced text through amendments, conference reports, and enrolled bills to the U.S. Code (the official compilation of federal statute) sections they modify. And it supports measurement of legislative text reuse and template language diffusion across policy domains and Congresses—identifying the boilerplate provisions, enforcement mechanisms, and definitional frameworks that recur throughout federal statute.
For example, a two-sentence provision establishing a grant program may be introduced in one bill, partially incorporated into a larger authorization measure during committee markup, and finally enacted through a conference report attached to a different vehicle entirely. The lineage layer reconstructs that path deterministically.
Figure 2. From Congressional XML to Queryable Graph: The Pipeline
One provision traced through four stages: what Congress publishes, how it becomes structured data, how structure becomes a graph, and what you can ask.

The five layers described above are not five separate datasets that happen to live in the same database. They are five different views of the same legislative process, connected at the provision level through shared keys. All five layers share a common coordinate system keyed to the bill and the atomic text unit, which allows traversal across procedure, amendment structure, vehicle classification, and lineage without duplication or inference.
Consider a single atomic provision—one paragraph of statutory text sitting in a bill currently moving through Congress. From that one provision, you can traverse the full database.
The lineage layer tells you this provision appeared as an untracked insertion during committee markup—it was absent in the introduced version and present in the reported version, with no corresponding amendment record. The amendment topology confirms it: no recorded amendment created this text. It materialized between versions through whatever happened in the committee's black box. The gate stack tells you the bill it sits in has cleared committee and floor in the House but has not yet been taken up by the Senate. The vehicle layer tells you this bill has a structural profile consistent with a shell vehicle—minimal introduced text, high overwrite ratio from floor substitution. The state machine tells you the bill is currently in the OtherChamber state, awaiting Senate action.
That is five layers answering five different questions about one provision, reachable through a single query path: atom → structural parent → document → bill → gate events, amendment DAG, vehicle classification, FSM state. The shared key—`bill_key`—is the integration mechanism. The layers are different projections of the same object.
Figure 3. Five Layers, One Provision: An Integrated Query
Each layer answers a different question about the same atomic text unit. All five are reachable through a single traversal keyed to the provision and its bill.

This integration is what makes the database more than a collection of useful tables. A researcher studying conference committee power can start from the lineage layer (which provisions did the conference committee add or remove?), traverse to the amendment topology (were those provisions previously the subject of floor amendments?), check the gate stack (how many gates had the bill already cleared?), and consult the vehicle classification (is this a must-pass vehicle where conference power is structurally amplified?). Each layer contributes a different dimension of the answer. No single layer could produce the full picture.
The same integration makes predictive modeling possible, as described later. A provision's survival prospects depend simultaneously on its detection context (lineage layer), its structural position in the amendment graph (topology layer), the procedural trajectory of its bill (FSM and gate stack), and the vehicle dynamics surrounding it (vehicle layer). These are not competing explanations. They are jointly observable features of the same provision, queryable together because the layers share a coordinate system.
An analogy: imagine trying to understand a city's transportation system. You could survey residents about their commuting preferences. You could count how many people arrive at each destination. Or you could map every road, intersection, traffic light, and on-ramp—the physical infrastructure that determines what routes are even possible. This project maps the infrastructure. The five layers are not five maps. They are one map with five kinds of information overlaid on the same streets.
What does that integration look like in practice? Consider again H.R. 4673 from the Introduction. It was introduced as a stand-alone bill. In standard congressional data it appears to go no further—"introduced" and nothing more. Behind the scenes, its text was taken up during the process that produced the 2018 FAA reauthorization. There was no structured amendment record in the usual sense; the text simply appeared in a later version, the kind of move the system classifies as a "Committee Amendment" insertion. The FAA reauthorization passed. Today, that provision from H.R. 4673 is in the U.S. Code—the law of the land. So: the _bill_ shows "failed" or "introduced only" in every standard dataset. The _text_ shows "enacted." The system traces that path from one provision, through one vehicle, to statute. That is the machine in motion.
Almost all existing congressional data work does one of three things: counts outcomes (how many bills passed?), measures ideology (where do members sit on a left-right spectrum?), or matches text similarity (does this bill's language overlap with that bill's?). Very little work reconstructs the actual procedural path legislation travels, the mutation architecture through which text is modified, the absorption mechanics by which policy migrates across measures, or the structural constraints that determine which paths are even possible.
This database enables a different kind of analysis—structural rather than behavioral, mechanical rather than ideological. Its value extends across multiple audiences and disciplines.
Figure 4. What Existing Data Sees vs. What This System Sees
The same bill at two levels of resolution. One row, or forty-seven provisions with seventeen different trajectories.

For political scientists, the framework opens at least five major research clusters. _Institutional power_: measuring negative agenda control through procedural topology, decomposing committee power into referral gatekeeping versus amendment gatekeeping, formalizing leadership procedural interventions as graph transformations. _Strategic behavior_: systematically identifying ghost bills and measuring behind-the-scenes lawmaking effectiveness, classifying vehicle strategies at scale, measuring conference committee text divergence from chamber-passed versions. _Temporal dynamics_: decomposing gridlock into preference-based versus procedure-based components, tracking amendment openness and deliberative structure over time, measuring reconciliation exploitation for non-budgetary policy. _Computational law_: building multi-Congress text lineage graphs tracking how the U.S. Code mutates through amendment, measuring legislative text reuse and statutory borrowing, constructing end-to-end provenance for enacted law. _Predictive analytics_: using gate stack configurations and amendment topology metrics as features for legislative outcome prediction, complementing vote-prediction models with pre-floor procedural filtering.
For journalists and watchdogs, the framework makes procedural manipulation visible and searchable: late-stage insertions, conference overwrites, vehicle substitution, gatekeeping patterns. A transparency dashboard built on this infrastructure exposes gate stacks, amendment topology, and vehicle classifications for active legislation in real time—reducing the information asymmetry between insiders and the public.
For legislative staff, it provides structural insight—where bills structurally fail, which procedural stages absorb the most policy, what typical gate sequencing patterns look like.
For legal scholars and historians, it enables procedural replay of any bill's trajectory, structural comparison across eras, and what amounts to "git blame" for federal law (tracing any enacted paragraph back to the specific amendment or version that added it)—backward through amendment, conference, and vehicle incorporation to its legislative origin.
The framework makes directly measurable:
Increasing amendment centralization over time. Floor amendment opportunities have declined as leadership has deployed more restrictive rules and structured the amendment process more tightly. The amendment topology layer provides the metrics—depth, branching factor, success rates—to measure this directly.
Shifts from committee authorship to conference dominance. The fraction of enacted text originating in conference committee insertions rather than committee-reported bills has grown, concentrating drafting power in a smaller set of actors. The textual lineage layer makes this measurable at the provision level.
Concentration of policy insertion at late procedural stages. Substantive policy increasingly enters legislation at conference or through manager's amendments rather than through the traditional committee-floor-conference sequence. The detection context classifications in the lineage layer reveal exactly when and where text enters the process.
The proceduralization of gridlock. Gate stack depth has increased over time, with bills encountering more procedural veto points regardless of underlying policy agreement. The framework can decompose gridlock into its preference-based and procedure-based components—a distinction central to legislative theory but not previously operationalized at scale.
Rising overwrite intensity in omnibus vehicles. Must-pass legislation exhibits increasing rates of complete text substitution, conference divergence, and shell bill usage. The vehicle inference layer tracks these patterns automatically.
Growth in provision fragmentation and recombination. Policy text is increasingly fragmented across multiple bills and recombined at late stages, making it harder to trace legislative intent or credit authorship. The lineage layer makes this pattern visible.
These are structural findings. They describe the machinery. They do not assign partisan blame.
The first research application of this framework is deliberately narrow: provision survival and incorporation dynamics. It was chosen as the initial target for several specific reasons.
First, provision survival sits at the intersection of three of the framework's five layers—amendment topology, textual lineage, and gate stacks—making it a strong test of the database's integrated capabilities. Second, it requires no predictive modeling, no behavioral theory, and no causal identification, which means the findings rest entirely on the deterministic infrastructure and are not entangled with contested theoretical assumptions. Third, it produces a new dependent variable—provision survival probability—that does not exist in current congressional datasets, demonstrating the framework's ability to generate measurement tools unavailable through other approaches.
The paper asks: conditional on reaching a given procedural stage, how durable is statutory text that appears at different points in the legislative process, and at which gates is that text removed? Using an analytic sample of 412,836 atomic text units across 6,214 bills in the 110th–117th Congresses (2007–2022), it introduces two outcome variables: provision survival probability (whether a specific text unit survives to enrollment) and procedural death gate (the specific institutional checkpoint at which non-surviving text is removed). Preliminary analysis suggests that survival varies sharply by detection context—text first appearing in conference reports survives at substantially higher rates than text traceable to recorded floor amendments—and that different gates systematically filter text from different sources.
The provision survival paper is subject to a rigorous validation methodology centered on XML-faithfulness: gate sequence fidelity is tested against Bill Status XML action codes, paragraph tracking accuracy is measured against Legislative XML structural nodes, and amendment operation recall is validated against amendment XML markup. All validation targets are deterministic, schema-defined, and reproducible. This validation framework applies specifically to the first paper's claims about the deterministic layer and does not extend to the broader research agenda, which will require its own validation strategies appropriate to each research question.
This application is a proof of concept. It demonstrates what the database can do. The broader value of the framework lies in the full range of research it enables—and in the extension described next.
The system described so far reconstructs the institutional structure of Congress—procedure, gates, amendments, vehicles, and textual lineage—from authoritative sources. That is the foundation: hard structural truth derived from the official record. What follows adds a layer of analysis without replacing or overriding that foundation. Embeddings never establish lineage or modify structural truth; they extend what can be asked.
The foundation tells you where a provision sits in the process, how it got there, what happened to it structurally, and whether it survived. It cannot yet see meaning. And without meaning, structure alone cannot explain persistence.
Two provisions in different bills, drafted by different offices in different Congresses, may attempt the same policy intervention using entirely different language. The deterministic layer has no way to connect them. They share no structural relationship, no textual overlap, no lineage edge. As far as the database is concerned, they are unrelated.
Embeddings give the system a new form of observation: semantic adjacency—the ability to see that two provisions are about the same thing, even when they share no words.
This works the same way tools like ChatGPT process language. When ChatGPT reads a sentence, it does not look up words in a dictionary. It converts the text into a long list of numbers—a vector—that represents the meaning of the passage as a position in a high-dimensional space. Sentences that mean similar things end up at similar positions, even if they use completely different vocabulary. That list of numbers is an embedding. The system uses the same technology: it feeds each provision through a language model and gets back a vector that captures what the provision is about.
The result is that "The Secretary shall establish a whistleblower protection office" and "A new office for the protection of individuals reporting misconduct shall be created by the Secretary" end up at nearby positions despite sharing almost no vocabulary. That proximity is measurable—a number between 0 (unrelated) and 1 (identical meaning). This is a new kind of relationship in the database: an edge based on meaning rather than structure or text identity.
Figure 6. How Vector Similarity Works
Sentences as positions in a meaning space; similar meaning maps to nearby positions and yields higher similarity scores.

Before introducing what semantic adjacency changes, it is worth being explicit about what the system already does.
The database is a knowledge graph — a network where entities (provisions, bills, amendments, committees) are connected by typed relationships (this provision _sits inside_ this section, this amendment _deleted_ that text, this bill _moved from_ committee to floor). The connections are as queryable as the entities themselves.
From a single provision, the system can traverse upward to its bill, across to the bill's amendment history and gate stack, forward to its conference treatment and survival outcome, and backward to prior versions that contained related language. It can move from a provision to its bill's committee, to that committee's historical report rate, to the Congress's political context. These are compound queries that cross multiple edge types—multi-hop reasoning through the institutional graph.
This is already a reasoning engine. Embeddings do not create the graph. They complete it, adding the one edge type it was missing.
The deterministic system contains containment edges, lineage edges, amendment edges, procedural edges, cross-reference edges, and adjacency edges. Semantic proximity is the first edge type that connects provisions based on what they say rather than where they sit or how they got there.
Once meaning becomes measurable, the system can observe phenomena that were structurally invisible:
Policy equivalence across time. Cluster every provision Congress has ever written that attempts the same policy intervention—regardless of bill number or wording. If a grant program has been introduced in 12 Congresses, rewritten each time, dying in committee under divided government but surviving when attached to appropriations vehicles, that pattern becomes visible. The database measures not just whether an idea survives, but under what structural conditions it tends to survive.
Idea persistence across party control. Track whether the same policy concepts reappear under different majorities, in different vehicles, with different structural profiles. Measure whether ideas persist through procedural failure and re-emerge in new institutional contexts.
Paraphrased incorporation. Detect cases where committee counsel rewrote, restructured, or combined provisions from multiple sources into new language that the deterministic layer cannot match. Surface the semantic near-misses that strict textual comparison alone would miss.
Semantic outliers within bills. Identify provisions that are semantically distant from everything else in their bill—potential riders (unrelated provisions added to secure a vote), late-stage insertions from unrelated policy domains, or conference additions that fall outside the bill's original scope.
Semantic distance between stages. Measure how much a bill's meaning changes between committee text and conference text. Quantify the semantic divergence that conference committees introduce, at the provision level, across the full legislative record.
Policy demand mapping. When many bills introduce semantically similar provisions but none advance, the density of attempts signals latent policy demand (repeated introductions of similar ideas that never find a path to enactment). Estimate whether that demand is likely to find a vehicle based on historical absorption patterns and current legislative conditions.
Historical analogue matching. For any provision currently moving through Congress, identify its closest semantic analogues in the historical record—provisions that said something similar, in similar structural positions, under similar congressional conditions—and observe what happened to them.
The epistemic boundary is strict: semantic proximity is a signal, not a finding. It suggests where to look; it does not establish influence or authorship. Structural truth remains grounded in authoritative XML and deterministic validation. Embeddings serve retrieval and prediction but never establish lineage or modify structural truth. The embedding layer expands what can be asked without altering what is known.
The database reconstructs the structure through which legislative power operates. Different audiences encounter that structure differently.
Current legislative tracking tools report what happened—who introduced a bill, where it was referred, whether it moved. This system analyzes every paragraph of a bill against the historical record of how Congress has processed text like it under comparable conditions. It identifies which provisions resemble language that has historically survived committee, which resemble language that tends to be stripped on the floor, and which resemble language that frequently reappears in must-pass vehicles after failing procedurally. A draft bill could be evaluated provision by provision: this section resembles language that historically stalls in committee; this clause resembles language that tends to be rewritten in conference; this structure resembles language that survives only when attached to must-pass vehicles. It estimates whether the structural profile of a bill makes it more likely to become a vehicle, to be absorbed into one, or to stall at a predictable gate. That transforms legislative intelligence from tracking what happened to evaluating, in real time, how the institutional machine is likely to treat a specific paragraph of statutory text.
Advocacy strategy often relies on informal knowledge of committee dynamics and past experience. This system makes those structural patterns measurable. An advocacy organization can see that provisions framed in mandatory regulatory terms have historically been rewritten in conference when originating in a particular committee, while similar policy goals framed as pilot programs have higher survival rates. They can see that policy ideas introduced repeatedly but failing formally often reappear inside omnibus vehicles. Strategy becomes evidence-based—grounded in the observable institutional record rather than anecdote.
Consider negative agenda control, one of the most influential theories in congressional studies. The theory argues that majority parties prevent measures that would split the majority from reaching the floor. Empirically, this has been tested at the bill level—what gets scheduled, what gets voted on. What has not been observable at scale is whether negative agenda control operates at the _provision_ level. Do majority party leaders filter entire bills, or specific text inside bills? Are majority-threatening provisions stripped before floor consideration while the rest of the bill advances? Does conference function as a second agenda control mechanism that rewrites provisions that would fracture coalitions? With provision-level survival data tied to procedural gates, these questions become empirically tractable. That forces one of the core theories of legislative organization to be tested at the level it actually operates.
For the first time, one of the core theories of legislative organization can be tested not just on which bills reach the floor, but on which specific pieces of text are allowed to survive the gates that precede it. This shifts the empirical foundation of legislative theory from bill-level inference to provision-level measurement.
The same applies to the literature on omnibus and unorthodox lawmaking. Existing studies rely heavily on case studies and bill-level comparisons. With provision-level lineage, scholars can measure what share of enacted text originated outside the final vehicle, quantify how much conference reports diverge from chamber-passed language, and detect when formally failed measures contribute enacted text through the ghost bill dynamic—across the full legislative record rather than selected cases.
Beyond testing existing theories, the framework opens research spaces that did not previously exist. Provision-level policy evolution: how enforcement clauses, definitions, regulatory structures, and grant formulas mutate across decades. Institutional filtering by text type: whether redistributive provisions are filtered earlier than regulatory provisions, whether definitional sections are more durable than enforcement clauses. Structural residuals as political intervention: if a structural survival model shows systematic deviations—provisions that survive despite high predicted death risk—those residuals may signal political intervention, becoming a measurable object in themselves.
For journalists and watchdog organizations, the system makes the institutional machinery inspectable. Which provisions were added after committee markup? Which first appeared in conference? How much of an enacted law originated in bills that never advanced on their own? Which gates filtered which types of policy? These questions have always been answerable in theory for individual bills through painstaking manual research. This system makes them answerable at scale, across the full legislative record, in a format that supports public scrutiny.
Most people look at Congress and see votes. Most data looks at bills and sees outcomes.
This system looks at text and sees filtration, mutation, absorption, survival, and procedural routing—at atomic resolution.
It reconstructs the machine itself—the procedural infrastructure, the textual assembly line, the gates and filters and vehicles through which every word of federal law must pass. With the addition of semantic embeddings, it extends from pure reconstruction into forecasting, connecting the structural record of how Congress has worked to probabilistic estimates of how it is working now.
This is a computable representation of legislative power at the level of language. Not at the level of votes. Not at the level of bills. At the level of the statutory text that institutions actually filter, retain, and enact.
A structural, replayable model of how law is actually assembled—at the level of language, not votes.
Casas, Andreu, Matthew J. Denny, and John D. Wilkerson. 2020. "More Effective Than I Thought: Accounting for Legislative Hitchhikers." _American Journal of Political Science_ 64(1): 5–18.
Cox, Gary W., and Mathew D. McCubbins. 2005. _Setting the Agenda: Responsible Party Government in the U.S. House of Representatives._ Cambridge University Press.
Eatough, Ella, and Jessica Preece. 2025. "Crediting Invisible Work: Congress and the Lawmaking Productivity Metric." _American Political Science Review_ 119(2): 566–584.
Fenno, Richard F. 1973. _Congressmen in Committees._ Little, Brown.
Kim, In Song, Carson Rudkin, and Luke Delano. 2025. "Bulk Ingestion of Congressional Actions and Materials Dataset." _Scientific Data_ 12: Article 1067.
Krehbiel, Keith. 1991. _Information and Legislative Organization._ University of Michigan Press.
Krehbiel, Keith. 1998. _Pivotal Politics: A Theory of U.S. Lawmaking._ University of Chicago Press.
Krutz, Glen S. 2001. _Hitching a Ride: Omnibus Legislating in the U.S. Congress._ Ohio State University Press.
Longley, Lawrence D., and Walter J. Oleszek. 1989. _Bicameral Politics: Conference Committees in Congress._ Yale University Press.
Oleszek, Walter J. 2016. _Congressional Procedures and the Policy Process_ (10th ed.). CQ Press.
Rohde, David W. 1991. _Parties and Leaders in the Postreform House._ University of Chicago Press.
Shepsle, Kenneth A., and Barry R. Weingast. 1987. "The Institutional Foundations of Committee Power." _American Political Science Review_ 81(1): 85–104.
Sinclair, Barbara. 2016. _Unorthodox Lawmaking: New Legislative Processes in the U.S. Congress_ (5th ed.). CQ Press.
Volden, Craig, Alan E. Wiseman, Thomas Demirci, Haley Morse, and Katie Sullivan. 2024. "Effective Lawmaking Behind the Scenes." Center for Effective Lawmaking Working Paper.
Weingast, Barry R., and William J. Marshall. 1988. "The Industrial Organization of Congress; or, Why Legislatures, Like Firms, Are Not Organized as Markets." _Journal of Political Economy_ 96(1): 132–163.
The following notes expand on each section of the main text at doctoral-level technical specificity.
The FSM is formally defined over a state set S of 15 elements with a deterministic transition function δ : S × A → S, where A is the normalized action ontology derived from Bill Status XML action codes. The system achieves 99.6% consistency across 6,214 bills (6,187 with no invalid transitions). The 27 inconsistent traces involve procedural irregularities such as re-referral after passage—rare events that the FSM flags rather than suppresses, preserving the audit trail. The transition function is strict: undefined (state, action) pairs halt processing and trigger manual review, ensuring the system never silently misrepresents procedure. The state ontology is deliberately coarser than the full set of possible procedural positions; the 15-state design captures the gates relevant to text filtering while remaining tractable for cross-Congress comparison. The FSM directly enables Paper 1.1 of the research agenda (negative agenda control as measurable gate leverage) by providing exact gate sequences and timing for direct tests of whether agenda control operates through procedural routing.
Gate stacks formalize the institutional veto point literature (Tsebelis 2002; Krehbiel 1998) as computable objects. Each gate Γ(b) = (g₁, g₂, ..., g_m) is inferred from FSM state transitions rather than coded from legislative histories, eliminating coder discretion as a source of measurement error. The four core gates (committee, floor, conference, enrollment) correspond to the primary institutional control points identified in the procedural cartel (Cox and McCubbins 2005), pivotal politics (Krehbiel 1998), and bicameral bargaining (Longley and Oleszek 1989) literatures. Gate density as a metric connects directly to Binder's (1999) legislative gridlock measures but operates at the bill level rather than the agenda level, enabling within-Congress variation in procedural exposure. This layer is the primary substrate for Paper 3.1 (the proceduralization of congressional gridlock), enabling decomposition of gridlock into preference-based versus procedure-based components.
The amendment DAG is constructed by parsing GPO Legislative XML amendment operations and linking each operation to its target text nodes. The graph is directed and acyclic because amendments apply to text states that are temporally prior. Overwrite ratios connect to Sinclair's (2016) observations about substitute amendments and strike-all replacements but provide continuous, computable metrics. Branching factor provides a structural operationalization of amendment tree complexity that complements the Rules Committee literature on structured versus open rules (Oleszek 2016). This layer is the primary substrate for Paper 3.2 (amendment rights and legislative openness over time) and Paper 1.3 (leadership control and procedural manipulation), enabling measurement of how amendment opportunities and leadership procedural interventions have evolved.
The vehicle inference layer formalizes Sinclair's (2016) typology of unorthodox lawmaking and Krutz's (2001) analysis of omnibus legislating as computable structural classifications. Shell vehicles are identified by low introduced-text-to-final-text ratios. Conference overwrites are identified by high conference divergence rates. These thresholds are design parameters, not estimated quantities. This layer is the primary substrate for Paper 2.2 (vehicle substitution and strategic bill shells), Paper 2.3 (conference committee power and text hijacking), and Paper 3.3 (reconciliation exploitation and budgetary procedure).
The atomic text unit—one `<text>` leaf node from GPO Legislative XML—is the observational substrate, stored in `text.atom` with structural parent reference, raw and normalized text, content hash, and ordinal position. The full containment hierarchy is materialized through `text.edge` (parent-child graph), with cross-references in `text.atom_internal_ref` and `text.section_ref_index`, dependencies in `text.atom_dependency`, and adjacency optionally materialized in `text.atom_adjacency`. Version-to-version continuity is established only through explicit lineage rules in `text.atom_lineage`, with permitted methods limited to deterministic_operation, exact_hash_same_address, and unknown. No semantic similarity is used to establish lineage. This layer is the primary substrate for Papers 2.1 (ghost bills), 4.1 (statutory mutation topology), 4.2 (legislative text reuse), and 4.3 (provenance tracking for enacted law).
The provision survival analysis estimates logit(Pr(T(u) = 1)) = α + β₁𝟙[d = floor_tracked] + β₂𝟙[d = floor_untracked] + β₃𝟙[d = conference_untracked] + γX_b + δ_c + ε_ub, with committee_untracked as reference category, bill-level controls (chamber, divided government, bill type), Congress fixed effects, and standard errors clustered at the bill level. The death gate specification uses multinomial logistic models with floor, conference, and enrollment as outcome categories. The sample restriction to bills passing at least one chamber floor ensures a common downstream procedural opportunity set. Causal identification is not claimed; the contribution is descriptive infrastructure. Validation is centered on XML-faithfulness: gate sequence fidelity (FSM-inferred transitions exactly reproducing Bill Status XML action code sequences), paragraph tracking accuracy (framework-inferred presence/absence matching Legislative XML structural nodes), and amendment operation recall (DAG-captured operations matching amendment XML markup). All validation metrics operate on deterministic, schema-defined objects.
The embedding layer adds `analysis.atom_embedding(atom_id, model_id, embedding vector, context_method)` to the schema. Context-enriched inputs are composed by walking the containment tree via `text.edge`, prepending structural ancestry to normalized text—e.g., "Title I — Section 101 — Subsection (b) — Paragraph (2): [text_norm]"—so that the embedding captures both semantic content and structural position. A single leaf-level text node is often too small to embed meaningfully in isolation; the ancestry context resolves this without altering the atomic unit itself.
Retrieval uses a hybrid strategy combining sparse and dense methods. BM25 sparse retrieval operates on `text_norm` via tsvector indexing (or ParadeDB pg_search for proper BM25 scoring), catching exact terminology, statutory citations, and formulaic language. HNSW indexing on pgvector provides approximate nearest-neighbor search on dense vectors, catching semantic similarity across different vocabulary. The two result sets are combined via reciprocal rank fusion. Every retrieved provision carries its full deterministic context—gate stack, amendment history, lineage trajectory, survival outcome—because the relational schema's foreign keys function as graph edges for multi-hop traversal: atom → bill → gate_events → committee_referral → congress → political_context. This traversal is SQL-native and requires no separate graph database.
For predictive modeling, the feature space combines three categories. Structural features from the deterministic layer: detection context, gate position, amendment depth, vehicle type, bill gate density, overwrite ratio. Semantic features from the embedding layer: similarity to historically survived and historically stripped provisions, semantic distance from the rest of the bill, policy domain cluster membership. Congressional context features: majority margin, unified or divided government, Congress-level base rates, committee-specific patterns. Training data comes from historical provision-level outcomes via `text.atom_lineage` and `analysis.atom_diff`. Models estimate provision survival probability, procedural trajectory likelihoods, conference divergence rates, and vehicle absorption probability. The epistemic separation is maintained throughout: embeddings serve retrieval and prediction but never establish lineage or modify structural truth.
The fifteen-paper research agenda spans five clusters (institutional power, strategic behavior, temporal dynamics, computational law, applications) plus three cross-cutting methodological extensions (state legislatures, comparative legislatures, regulatory procedure). Each paper builds on specific layers of the core framework: Papers 1.1–1.3 rely primarily on the FSM and gate stacks; Papers 2.1–2.3 on textual lineage and vehicle classification; Papers 3.1–3.3 on temporal analysis of gate stacks, amendment topology, and vehicle patterns; Papers 4.1–4.3 on lineage graphs and cross-reference resolution; Papers 5.1–5.3 on the integrated framework including the embedding layer. The state legislature extension faces the greatest implementation challenge due to heterogeneous procedural rules and varying XML availability across 50 states. The regulatory procedure extension (modeling notice-and-comment rulemaking as a deterministic FSM) would extend the framework beyond the legislative branch entirely, enabling unified computational analysis of how policy moves from bill text through enacted statute to implemented regulation.